Description
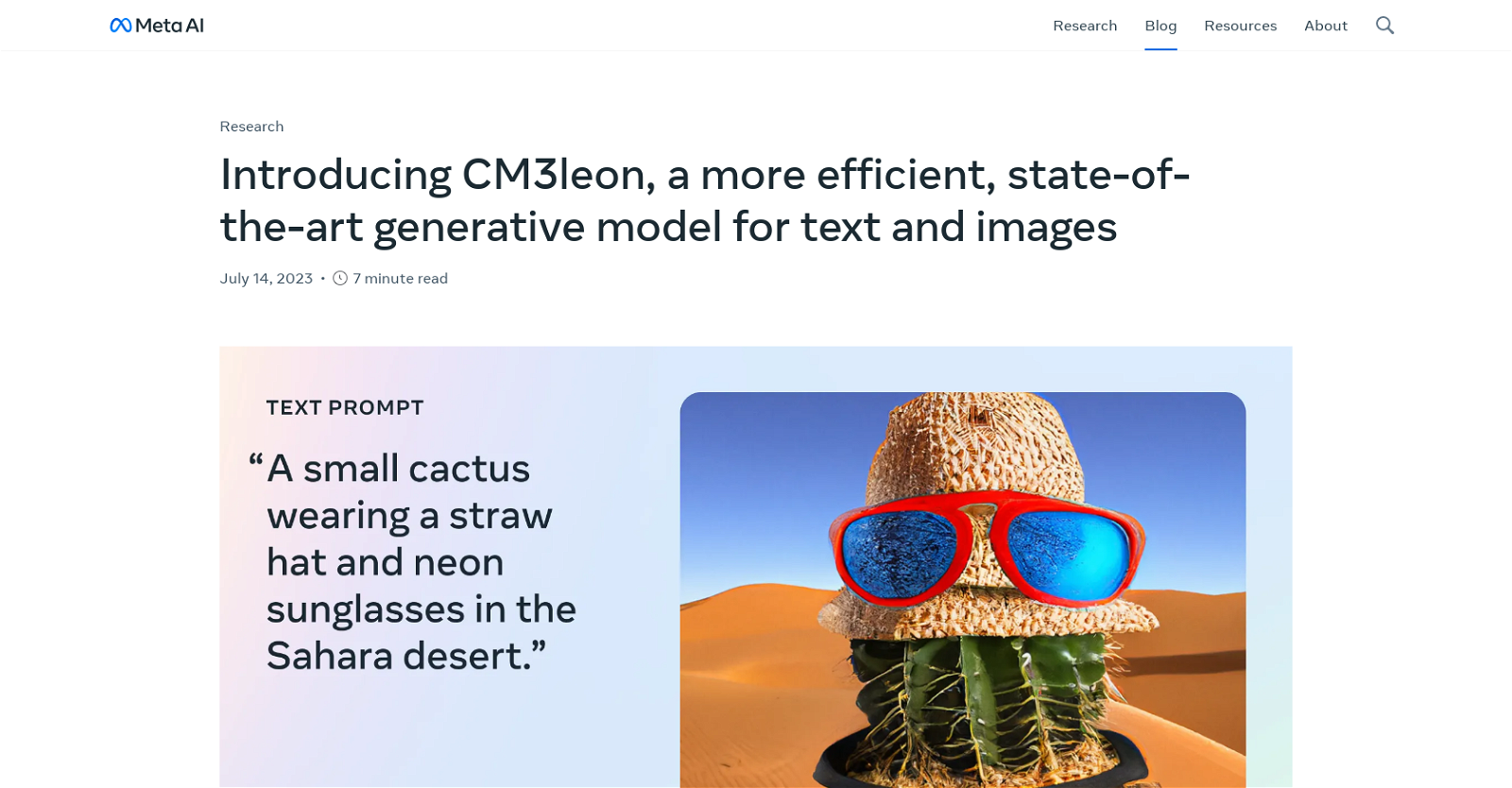
CM3leon by Meta is a cutting-edge generative model that excels in text-to-image and image-to-text generation tasks. Trained using a unique recipe adapted from text-only language models, CM3leon achieves state-of-the-art performance with low training costs and high efficiency. It outperforms previous transformer-based methods and showcases impressive capabilities in complex object generation and text-guided image editing tasks. With multitask instruction tuning for both image and text generation, CM3leon is a valuable tool for various vision-language tasks.
What is this for?
CM3leon by Meta is a state-of-the-art generative model that enables text-to-image and image-to-text generation with impressive performance and efficiency.
Who is this for?
CM3leon is designed for researchers, developers, and AI enthusiasts looking for a versatile and high-performing generative model for vision-language tasks.
Best Features
- State-of-the-art performance in text-to-image generation
- Multimodal functionality for both text and image generation
- Efficient training and low inference costs